1
通过前面几篇文章,我们已经弄清了做一款商业产品所需的前期准备工作,对要做的产品做出了价值和机会判断,接下来就要确定产品真正做成什么样子。
产品通过功能、界面、内容传递应用价值,用户也是通过这三点来触达和体验产品。所以狭义的产品经理日常执行工作,也是重点围绕这三点来展开。
分两篇来说,这一篇说功能与交互,下一篇说界面和内容。
之所以要把功能和交互放在一起,是因为这两者密不可分,用户要使用一项功能,就离不开人机交互。
我们从下面这张图看起。期望转型或已经成为产品经理的同学都应该见过这张图。
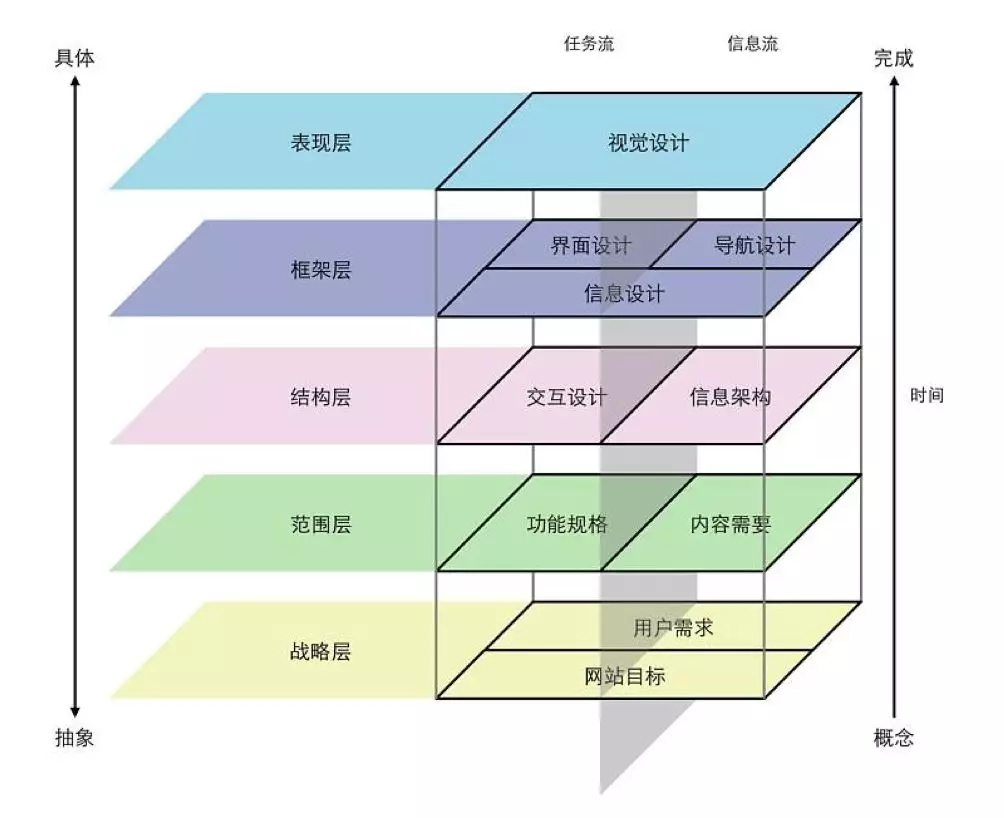
战略层,通过对外部环境(政策、经济、技术、市场)、内部资源优势及用户需求深入分析之后,确定了产品的目标和资源计划、运营计划。
范围层和结构层,即是本文讲述的重点。
框架层和表现层,放在下一篇文章中阐述。
2
我们设计一个产品,确定包含哪些功能(功能范围),这需要系统化思维、结构化思维的过程。
一个系统,包含了参与方、互动关系(生产、消费)和反馈链,反应到产品中,就是产品谁来用(用户角色),他们目标是什么,产生和消费了什么,资源如何流动?
比如电商平台,必要的参与方有平台、商家、顾客。
平台方要建设和运营平台,服务好商家和顾客,让他们在线上完成交易,把制定的交易规则落地到流程中,需招募商家,举办活动,充分满足商家的商品曝光和销售需求,还需要分析数据,观察商家、顾客的行为,追踪平台运营的各项指标。
商家需入驻平台,编辑商品和上架、接受咨询、处理订单、发货、进行售后服务、收款提现、对账等,还要做推广,维护客情。
顾客要搜索挑选商品、比价、下单、付款、收货、评价……
这里以电商的业务举例,一是假设大家对剁手熟悉,容易理解。换作其它产品也是用同样的系统化思维切入,按参与方分解子系统,梳理相互关系、资源流动与反馈链条,从而确定整个系统的功能范围。
在本系列第一篇,回顾了互联网产品历史和分类,每种类型的产品都可以用系统化思维来分解参与方角色,用功能来框定角色的责权利。
二是因为电商是一种典型的交易模型,从更高的维度来看,很多人类活动和产品模型都是广义交易模型,有生产方和消费方,过程中发生着信息、资金、物质的交换。
一个系统的实体要素,可以总结为五大项:人、财、物、活动、管理。活动是人、事物的核心事件和行为,比如发生在公司里的生产、研发、销售、市场、财务等经营活动,在学校里,主要活动有教、学、科研。
C 端用户也类似,用户面对自身、家庭、工作所进行的学习提升、娱乐休闲等,就是主要活动。管理,就是对前四者的计划、配置、监控、统计。一个产品的功能范围,就要覆盖这几个方面。
当某项活动足够复杂,或者信息密度低、流通不畅的时候,必然要诞生新的角色提供相应的服务,这就是中间商、中介。对于我们的启发有两点。
一是能不能发现成为一个中介的机会。比如新浪微博早期没有自建广告平台,「微博易」之类的中介公司乘势崛起,建设了中间平台,撮合广告主和大 V 的交易,盈利状况非常好。微信公众平台就比微博更聪明,在功能规划里包含了广告平台,没有把肥肉丢给外人。
二是能不能发现干掉中介的机会。这方面就不多说了。
回到一个功能的设计,即是围绕这五项展开。也是另一项重要的思维——结构化思维的用武之地。比如确定了参与方后,再细分参与方的角色、使用场景、行为流程……方法是确定每一层的分类方法不断细分下去,直到落实到可以在页面上所能进行操作的功能上。
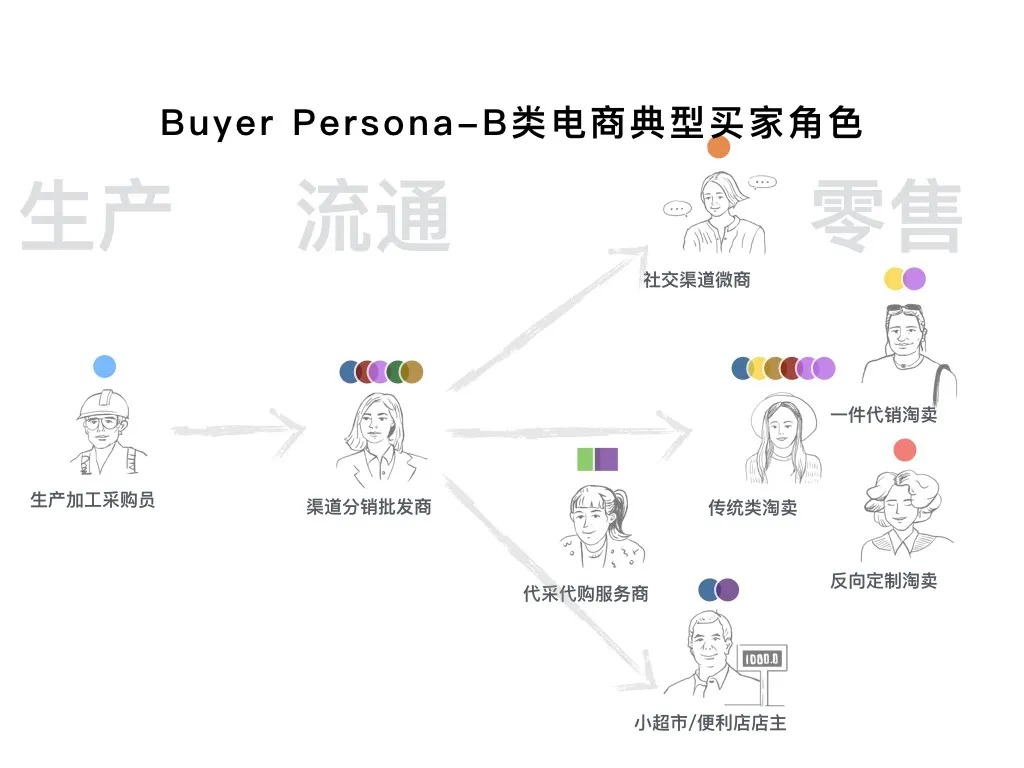
如上图是对 B 类电商典型买家角色的细分。产品经理就是在不断界定产品的服务对象和服务环节,结合机会和自身优势,将某类对象的主要痛点充分地解决。
确定功能范围这项工作,最终的交付成果,可以是 Feature List、用户故事地图、用例图。贴几张图看一下。
3
最难同时也是最重要的是从全面、广泛的功能中确定核心功能。一个产品功能十分全面,不代表是一个好产品,也许是中庸的代名词。产品的功能复杂,也只能说明产品经理具备复杂化的能力,更有价值的是复杂化后回归简单的能力,当然,很多时候产品经理可能都不具备精确复杂化的能力……
产品的功能范围,可以体现一个产品经理对判断力的信心,没信心的时候,往往就追求大而全,指望能面面俱到,通过广撒网的方式不丢失用户。真正有信心的产品,核心的功能一定是较为单一明确的。
从最终产品交付来讲,一开始就试图设计一个完善的系统是不可能实现的。虽然能一定程度避免返工,但无法确保最终市场的胜利。尤其是从无到有这个阶段,速度很重要。
这方面可以和产品需求 KANO 模型进行关联。
4
结构层,简单谈信息架构。信息架构确定如何组织和展示内容、功能,用户通过功能的入口、操作的路径和可见的内容功能集合来感知信息架构是否合理。
这里面最重要的是同理心的运用。在我的经验中,最容易出问题的是菜单、导航、快捷方式、功能层级等按照非常严谨的方式组织起来,逻辑上完全正确、标准,但用户使用起来变扭,感觉不方便。
反观有些产品貌似杂乱,但用起来却很顺手,相信不少人都有过类似的体验。大数据里常举一个伪例是啤酒和尿布放一起,在这里倒可以作为以上道理的例子。
在需要的地方出现,这是信息架构和交互原则里最重要的一项。
5
再来说交互。交互就是人和机器的互动。
- 人用眼睛看屏幕,屏幕有大有小;
- 人用手指触摸屏幕,分左右手、拇指食指,可拖动、点按、长按、捏合;
- 人操作鼠标,有单击、右击、双击、拖动、滚动。有移入、移出、按下、抬起。
- 人可以操作键盘、发出语音指令……
人通过器官、设备向机器输入,机器输出过程和结果信息,这就是交互。交互设计就是对输入输出对象的格式、大小、操作方式、反馈方式的设计。

产品经理很重要的一项工作就是交互原型设计,有的公司会把这项工作细分出来,交给交互设计师。
产品经理如何快速入门交互原型设计?有一个极简单、直接的方法,它就是(画重点):
Google、Apple、Bootstrap 三篇关于交互和设计的文档,用三周时间,每篇看三遍以上。
- 《Material Design 》:https://www.material.io/
- 《Apple 人机界面指南》:https://developer.apple.com/design/human-interface-guidelines/ios/overview/themes/
- 《Bootstrap 中文文档》:https://v3.bootcss.com/css/
因为交互设计里有太多的知识,比如布局的栅格系统、比如几十种典型的表单组件规范……
授人以鱼不如授人以渔,熟悉了上面三篇文档,不管是做交互原型,还是做界面设计,从思维、原理、方法上都有系统的把控。
(* 文中图片来源于互联网,版权归原作者所有)
来源于:微信公众号「关耳爷」