形形色色的数据库
——一文读懂 OLTP 和 OLAP
1
为什么会有这么多类型的数据库?
因为满足不了用户使用数据的全部需求。
数据使用说起来很简单,概括起来就是「读、写」二字,但实际操作中,无比复杂。
数据业务在大的方向上有两类,分别是交易型业务和分析型业务。
你可能见过这两个词:OLTP 和 OLAP,基本上就是对应这两种情况。
数据库为满足业务需求,也分为两大类:交易型数据库和分析型数据库。
交易型数据库是什么?
交易型数据库用于业务系统数据的增、删、改、查。又称为操作型数据库、事务型数据库。
业务系统就是我们平常所能接触到的各种功能系统,如企业经营过程中使用的各种管理系统,包括设计、研发、制造、销售、人力、财务的各种系统;个人生活娱乐、工作中用到的各种应用,如电商、微博、微信等。都可以看成业务系统。
这些系统,需要把我们提交的信息实时保存下来,也需要把保存好的数据展示出来,按用户各种查询条件过滤数据,还可接受用户的修改、删除。
通常,完整的一段信息会被分开存储,如一篇文章,分成标题、正文、作者等部分,按固定的结构存储,这就叫「结构化存储」。这种存储方式,有很多优点,因为粒度细、结构规整,想局部、全部地读写数据都很方便,效率非常高。
交易型业务,有两个字非常重要,即「实时」。数据要实时地成功写入,快速地读取。想想看,发生了一笔充值或消费的操作,数据却没有被实时地记录,后果非常严重。
哪种数据库用来支持交易型业务?
适用于以上场景的数据库,主要是大家所熟知的关系型数据库,如 MySQL、Oracle、SQL Server、PostgreSQL 等。
它们共同特点是一个库里会有多张表,相当于一个 Excel 文件中有多个 Sheet 页。每张表会存储相同业务和结构的数据,如商品表,只存储和商品有关的信息,有商品名称、商品规格、商品描述……订单表,只存储和订单相关的信息,订单号、订单金额、下单时间……每张表有多个列(字段)存储这些数据,同 Excel 文件的列一样。
这些数据库,有的是商业公司开发的,有的是开源的。一般来说,商业数据库,会支持更多的特性,性能、稳定性也更高,有好的服务保障。关键行业应用的数据库,如银行,用的都是商业数据库。
开源数据库应对一般的使用场景也没有问题,还可以按需调优和改造。很多国产关系型数据库就是基于开源关系型数据库改造而来。
关系型数据库除了上述几种,还有一类轻量的产品,以 SQLite 为代表,非常适合手机等移动设备应用本地存储。
只有关系型数据库就够了吗?
关系型数据库太「规范」了,事先需要有大量的结构设计(即建模)工作,到用的时候需要知道结构才能取出所需要的数据。读写的速度也不行,因为它最终要存储在硬盘上,如果数据从内存中读取,速度可以保障,但丢失风险高。
我们的目的是用数据,可不想耗费精力在它的结构上,通过结构化对数据进行使用,只是一种方法和手段而已,并不是一定得把数据结构化后才能用。况且,有时候结构本身是数据的一部分,拆成行、列的存储形式用起来反而不方便。
有些数据,非常适合用 JSON 的结构存储,如下图。再把这种 JSON 文档存储在不同的「单元格」中,这种存储方式和上面关系型数据库的原理有本质的差别。实际上这种方式就是 NoSQL 数据库的一种类型,叫做文档数据库。代表产品是 MongoDB。用户可以事先不关注数据库结构,只需关注文档内部的结构,每个文档的内部结构都可以不同,这样一来更贴合人类「自然」的使用。
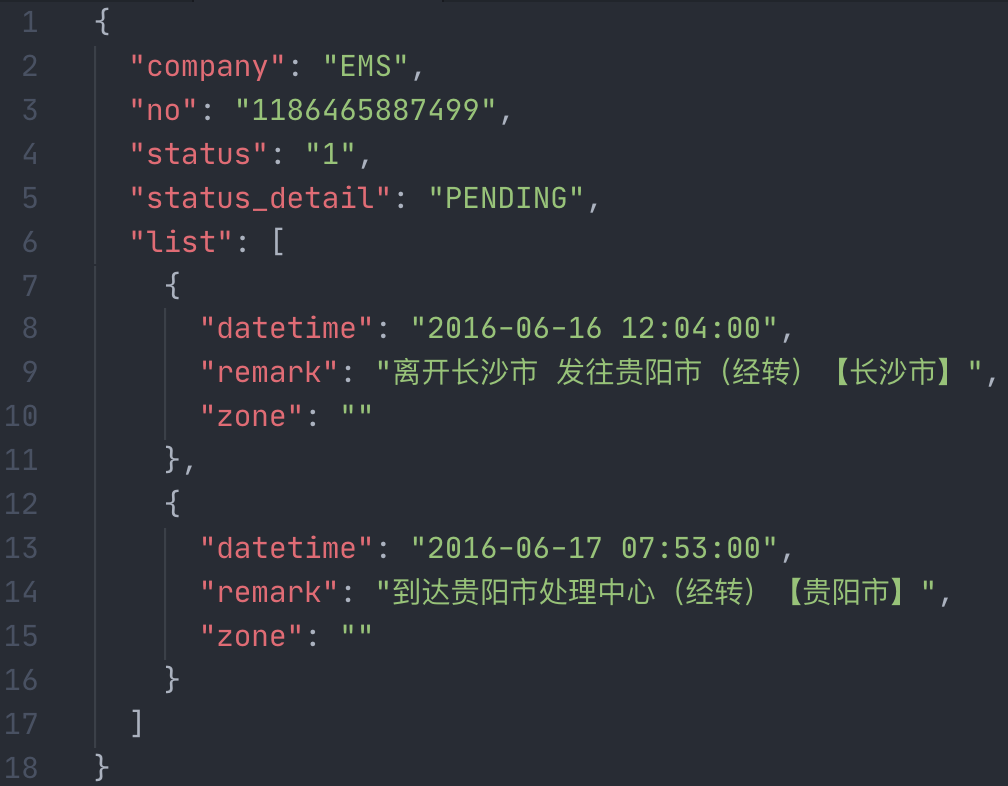
NoSQL 除了文档型数据库,还有键值型数据库、列式数据库、图数据库、时序数据库等。各自典型的代表有 Redis、HBase、Neo4j、InfluxDB 等。
NoSQL 数据库为什么也有这么多种类型?
简单来说,有两个原因,一是数据本身的特点;二是出于使用场景的需要。
一种新技术或新产品的出现,一定是为解决某个具体的痛点。
比如 Redis 是基于内存的键值数据库,键值这种存储结构,类似于查字典,查询速度非常快,数据又是在内存读取,比硬盘快很多倍。它的应用场景在于较稳定不变的数据的高频读取,不必每次都从关系型数据库中查询,所有一般应用在数据缓存的场景中。
时序数据,即按照固定频率不断生成的周期性数据,一般物联网设备、日志数据等都会呈现时序特征,这类数据有非常显著的特点,比如说插入频率较为稳定,不会像天猫双十一活动非常高的并发写入,写入的数据几乎不被更新,不会像订单数据那样进行状态更新,也很少会删除单条数据,一般是对过期数据批量化删除。时序数据偶尔丢失几条,不会对整体业务造成太大的影响。它们的某些维度,可以合并存入,降低存储成本,如某台设备的 ID、IP 地址、甚至是地区,可以是类似「合并单元格」的存储方式,这实际上就是时序数据的压缩技术,可以有效节省存储空间。针对以上特点进行优化设计,就产生了专门的时序数据库。
图数据库,和图片、图像完全没有关系。它擅长实体关系的存储和表达,如社交关系、投资关系等,关系型数据库也能做到,多个实体可以通过主外键来建立关联,多对多的关系需要产生一张中间表来关联,如果存在大量的这种数据,关系型数据库就会耗费大量的存储资源,关联查询和递归查询效率也会比较低。即使是同一实体,如果关系穿透路径较长时,有时也会低到不可用的地步。图数据库利用节点和边的结构,比较完美地解决了上述问题。
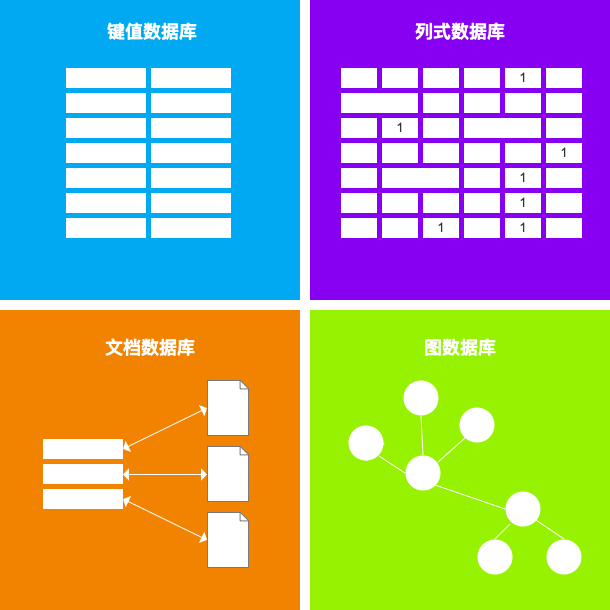
从 NoSQL 这里,就有了向分析型数据库过渡的倾向,这一点在列式数据库上有明显的体现。列式数据库典型的代表是 HBase,顾名思义,在物理存储上,列式数据库按列存储数据,最大的优势是获取「局部数据」更快,在数据统计分析的场景下,我们通常是按列进行操作,比如对价格一列进行求总和、平均值、最大值、最小值等(术语上称为「聚合查询」,是分析的基础),这一列数据物理上存储在一个区域,一次就可以读取,而如果是按行存储,需要读取每一行,才能从每一行数据中找到「价格」那个单元格,这就是它最大的优势,所以数据分析业务,即 OLAP,列式数据库有很高的性能。
这种列式存储的结构,也非常有利于分布式存储。天然适合大数据。2
分析型数据库有什么特点?
简单地说,分析型数据库,是面向分析的,而不是面向记录数据和更新数据(这是交易型数据库做的事情)。
分析就是通过对数据进行有逻辑的计算,得出新的数据,新的数据可以印证一定的假设。想要做好数据分析,要求分析型数据库有以下特点:
首先,它需要存储大量静态的数据,基于尽可能多的数据,才最有可能还原真实情况。其次,需要能很快地取出计算所需的数据,这对于快速得到计算结果至关重要。最后,取出的数据可以很快地得到聚合的结果。
上面已经说到,列式数据库在前两点上已经支持的不错了。
换个角度来说,分析就是尽可能多角度地看待某项定量数据。多角度,就是「维度」,定量数据,就是「度量」,分析的核心内容,围绕的就是这两个关键词。
而这两个关键词的背后,就是离散数据和连续数据,两者之间相互转化的主要手段,就是聚合查询。所以最后一点,能快速得到聚合的结果,也是分析型数据库的着力点之一。由此诞生了很多 OLAP 的引擎。我们耳熟能详的有:Hive、Presto、Impala、Clickhouse、Greenplum、Doris、Druid、TiDB。
这些大数据开源工具,很难严格地界定它们是数据库,还是 OLAP 引擎,还是交互式查询(即席查询)引擎,正是由于上面提到的最后一个要求。它们通过各种技术原理和方法,实现能够快速地进行维度构建、关联、转换和度量的计算,最终达到快速获得分析结果。
另一方面,分析型数据库还得考虑易用性,对于我们来说,目前最好用的分析方法还是属 SQL 语句(尽管对普通人还是很难)。对于存得多和取数快,偏偏是 NoSQL 的长项,如何让分析型数据库良好兼容 SQL,也是分析型数据库核心要面对的问题。
以上是「关耳爷」微信公众号的小输出,请笑纳。