网站流量统计的方法
想要得到网站被访问的数据,有三种方法。
第一种是网站自身开发数据统计的功能,这种方法只有特殊数据需求的并有技术实力开发的网站采用。
第二种是利用第三方流量统计系统,如百度统计和Google Analytics等,原理是需要统计数据的页面都调用第三方提供的一个脚本代码,这个脚本完成数据的收集和传输功能,第三方接到数据后完成处理和展示供用户查询。
最后一种方法是使用统计软件处理和分析服务器上的web服务软件生成的日志文件,如IIS、Nignx、Apache的日志,需要将日志文件按一定的周期切割好,一般是每天,把这些源数据导入到软件中处理和分析。<!–more–>
第三方统计系统
使用第三方统计系统的优点是简单,注册好账号,添加网站,系统会自动生成统计代码,将代码嵌入网站页面中即可。缺点是下载和解释站外的脚本资源会影响速度,尤其是第三方路线环境不好或者负载高的时候,都会导致页面整体载入速度慢。小型的统计系统出现过这样的问题,如51.la,cnzz等,另外是安全和隐私问题,毕竟运行的是第三方提供的一定程度上未知功能的脚本。
使用百度统计据说会提高百度收录的权重,另外百度统计还提供了一些有用的应用,如本文章右侧出现的返回顶部按钮,就是百度统计的脚本提供的,这个功能只需要在百度统计后台开启就可以,还有百度商桥(百度免费提供的客服系统)也受百度统计代码控制。
Google Analytics十分强大,胜出百度统计好几个级别,用起来相对困难,但流量术语、概念的定义和分析比百度精准,缺点是上手难一些,速度更慢,据说被墙有时数据会不准。
百度的核心产品和模式其实都是照着Google抄的,典型的Search engine+Google Adwords+Google Adsense三套马车的架构,不能不说这套模式真是Google最伟大的发明,搜索引擎面向普通用户,Google Adwords面向商户和广告主,Google Adsense面向网站主,当用户输入关键词到达含有Adsense广告的网页时,首先这个页面一定是和用户输入的关键词有匹配关系的,这也是搜索结果质量高低的直接反映,Adsense所引入的广告和页面内容作了第二次匹配,经过精密的算法,广告和内容的关联性非常强,当用户对检索到的内容满意时,广告常常也会在他的关注之内,这就为广告主提供了价值,而广告主可以在Adwords平台设置受众的细分,如性别、年龄、行业、地区等。
Google怎么确定的了用户的社会属性?这是Google Analytics和Adsense产生的Cookie直接起了作用。Cookie是寄存在你电脑上的一个文件,Google对你所使用的终端环境设定了唯一标识符,当你浏览了大量的含有Analytics和Adsense脚本的网站时,你的数据在不断地被Google搜集着,不要怀疑使用这两个产品的网站的数量级有多大的规模,统计是免费提供给站长用的,Adsense是能帮助站长拿到美元(广告收入)的,你访问的网站中大部分都含有其一,或者两者并用,只不过你不知道而已。
Google知道你用什么设备上装的什么浏览器经常在什么时段访问什么网站,知道在浏览器上搜索的关键词是哪些,通过大量的数据沉淀分析,从而得到行为背后你的精准画像,很多时候Google比朋友都了解你。
这就是免费的意义与免费的产品要做强做好的真谛。
百度的核心产品构架完全照搬Google,而且更为极端,推出了竞价排名,操纵了搜索的结果列表,另外做了一些本土化的工作,因为抄得相对底层,不像腾讯那样都是能被普通用户看出痕迹的表面的抄袭,所以人们往往不提百度的抄袭,其实山寨王的称号在我看来更应该颁发给百度。
使用第三方统计主要是快速理解它的术语以及易混淆的那些概念,如PV、UV、IP。
这三者的区别可以举个例子说明,在一个使用局域网上网的部门里,共有10台电脑,其中1台电脑装了2个浏览器,一个MM看到一个有趣的页面,就在QQ群里分享了链接,另外9个人都打开了这个页面,装两个浏览器的哥们儿还用两个浏览器都打开了一遍,其中3个人被另外的标题吸引又贡献了一次点击,那么PV、UV、IP的数值分别是多少呢?答案是14、11、1。这是最初级的。
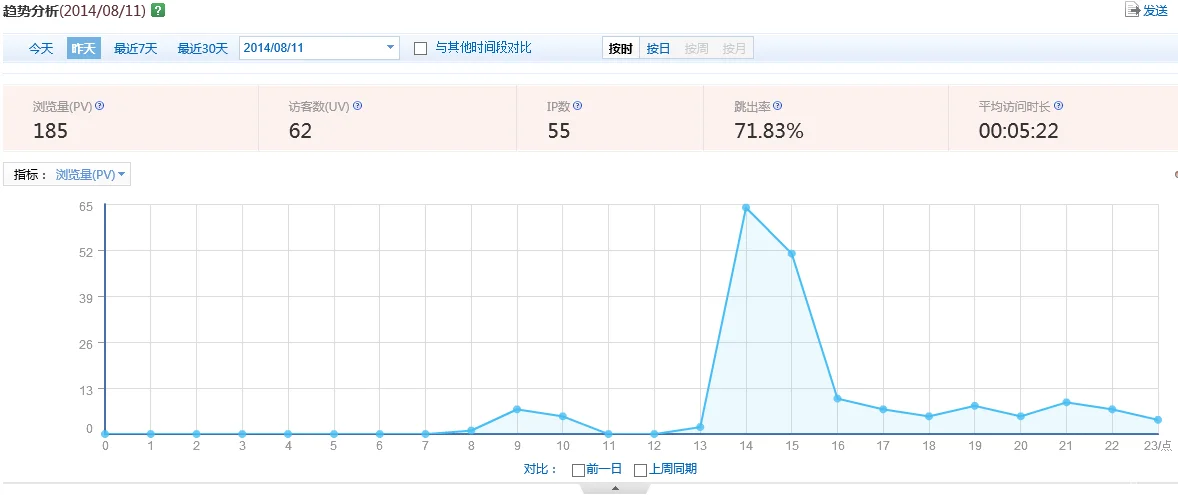
这是我上次在微信朋友圈里分享了《把网站放到路由器里》后百度统计后台的数据,可以看到在我分享后不到1个小时里,访问数据就达到了最高点,随后就是一个长尾,在晚上9点的时候有个小突起,这说明,刷朋友圈的频率是非常高的,大部分可能有事没事就在刷朋友圈,到了晚上9点,很多人闲下来了,又是一个访问小高峰。
能判断出微信朋友圈这个模块的粘性非常大。这是数据得出的结论,其实不用数据直接观察就能得知。
看到大致是60个朋友打开了我的分享,这里边肯定是对我比较关注,或者对我分享的话题比较关注,没打开的则正好相反。打开这条分享的有70%多没再点击页面上的其它链接就关掉了,剩下的30%大概又看了其它4、5篇文章。
我还能看到哪些地区的朋友在什么时间点打开的我这条分享,以及打开了多长时间。这就能让我大体判断,我的哪些朋友对技术文感兴趣,谁又读完了整篇文章。
这仅仅是一篇分享带来的数据,如果我分享的最够多,能得到非常多的信息。
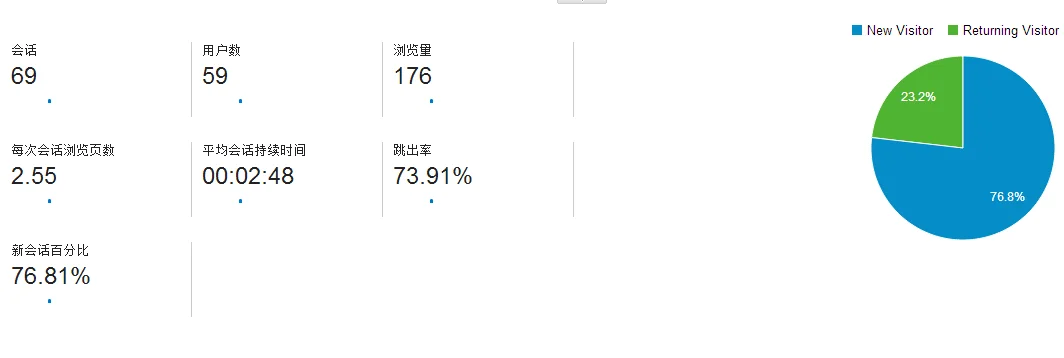
Google和百度统计到的数据大部分相近,唯一平均会话持续时间相差较大,这说明两者的算法肯定不一样,Google是2分钟多,通过常识判断Google更准一些。
服务器日志分析
典型的一款服务器日志分析软件是Awstats,基于Perl,方便的做法是直接部署在web服务器上,设置好web日志格式,Awstats就可以自动处理分析了。
由于日志的数据由全部http请求生成,所以使用这种方法统计是最全面和准确的,能统计出不同类型文件的流量也是它的特色之一,另外它也能区分出搜索引擎蜘蛛爬行的记录。
有条件的话可以搭配第三方统计系统一起用。这种统计方法只用过一段时间,总体来说还是不如第三方方便。
想看现场的这里有个demo。
这个工具便于发现流量负载重的原因,也能直观地发现死链,还能用于ftp、mail服务的统计,总体还是技术运维工作用的多些。
网站流量统计的目标
网站流量是最基础的运营数据,手里有一个站,通过流量分析很容易能看到有哪个地方的人通过什么设备和浏览器在什么时间访问了哪些页面,他是怎么进来的,在哪些页面停留的时间长,哪些页面停留时间短,从哪个页面又进入了另一个页面,最终从哪个页面退出。
这是偏向于个体的一类数据,数据积累多了,还能看出来网站最受欢迎的页面是哪些,哪个地区的用户最多,网站经常被访问的时段是什么等,哪个投放的渠道性价比最高等。
知道了这些,才能真正掌握这个站的现在的业务是什么和未来应该是什么,数据反应出来的和脑子里所想象的有时候正好相反。
统计能达到什么目标呢?有以下两个方面。
趋势预测和受众分析
趋势预测是基于一种规律,足够大的垂直电商甚至能大致判断出某地区受众大致发工资的时间。每个月相同的日期访问量开始增大,但订单量有限,此时很多商品被加入到购物车中,过了某个点,订单支付数量上升,经年累月如此,就能知道该在什么时候推什么活动,什么时候调价。
根据历史的曲线,预知下个相同周期的变化,以便提前防备抑制或者助势推进,这个不像股票那样阴晴不定。指导我们该在什么时间做什么事情。
受众分析其实也是趋势预测里的一种,我们总是能观察到一个周期里用户和设备的属性,就要服务好80%的用户和设备,这个是最简单的道理。但是更需要对比每个周期用户和设备的变化,比如网站的女性用户越来越多,用户的年龄越来越大,使用移动设备的用户越来越多,这是否和自己的定位相符?是否需要内容改版?是否需要更进一步做响应式的优化?
有的产品是跟着用户一直在成长,一直满足他各个阶段的需要,服务的就是这一类人。多见于高端、定制、圈子型的服务。
有的产品就是服务的一个周期,产品核心一直不变,变的是用户,一批人走了,另一批人又来到。这类多见于工具型的应用。
追溯大幅变化的原因
这里所说的是排除了正常范围内的异常情况,统计分析能实现这样一个目标:找到曲线突变的原因。
是内部的技术原因?如致命的服务停止,或者线路环境不好访问速度变慢,用户忍受不了下次不来,或者是停掉了哪一类受欢迎的内容或服务……
还是外部的因素?比如做了广告的投放,或者发布了有争议的内容,或者是受到了大V的分享等。
通常来说,原因肯定往往不只一个,有了数据统计,我们都可以把它们找出来,并建立合理的关联。
网站流量统计的内容
大的结构就是两方面,一是客体本身,即页面,二是主体的数据,即访问者的情况。这是相对较老也交易掌握的分类方法。
页面本身
注重的是页面的数据,这部分主要是受访页面、入口来源、上下游关系、页面点击热点图、数据来源等。其中数据来源分为直接访问和外部引荐,直接输域名进入和在收藏夹里点击都属于直接流量,外部引荐又有搜索引擎和外部链接,社会化分享繁盛以后,又把社会化分享也单独拿了出来。
访客属性
关注的是来到网站的用户的数据,包括地域分布、新老访客、忠诚度、系统的环境和访客的社会属性等。
更先进的统计系统逐渐向以受众群体为基础维度过渡,也就是围绕访客的特征、兴趣、位置、行为(过去的和现在的)、事件、技术、状态和转化来组织数据。这种方法是旧方法的系统再加工,旧方法中得出的数据还要人为地建立逻辑关系来处理,而先进的系统在尝试把需要人做的工作搬到它的内部,尝试直接展示出更接近结论的数据。